|
|
Acorn Solutions Inc. |

|
| Company Info | Areas of Expertise | Selected Projects | Customers | Downloads | In the Works... | Contact Us |

|
In the IMAS project, we also created redundant reporting infrastructures for hot standby in case of a monitoring system failure. Many other types of events can be detected and ticketed by this solution. We worked with the customer to determine that these particular events were the most important ones to detect for their users. |
The solution utilizes off-the-shelf software agents and custom configurations to: detect system events, report them via SNMP traps, and then turn these SNMP traps into Help Desk trouble-tickets. The off-the-shelf components used in this case were: Microsoft's SMS, HP Openview, Seagate NerveCenter Pro, and Remedy "Action Request System". An architectural overview for this system is shown below:
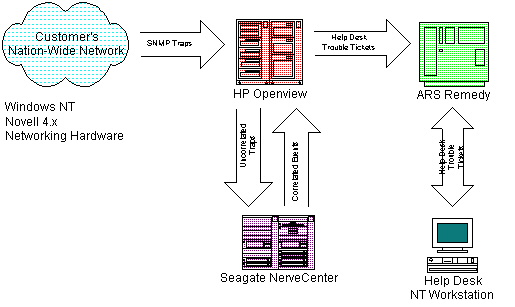
The types of events that are currently being detected and trouble ticketed by this system include:
- Viruses detected during auto-scan
- RAID disk failures
- Login attempt limits exceeded
- System backup job failures
- UPS detected power failures
- NT service startup failures
- Disk utilization limits exceeded
- CPU utilization limits exceeded
- Microsoft SMS inventory process failures
- Software package distribution failures
At the conclusion of our role in the project, this system was already monitoring and trouble ticketing over 3000 nodes.
| Copyright © 2003 by Acorn Solutions, Inc. All rights reserved. |